HotStuff 共识算法详解
1 前言
HotStuff提出了一个三阶段投票的BFT类共识协议,该协议实现了safety、liveness、responsiveness特性。通过在投票过程中引入门限签名实现了O(n) 的消息验证复杂度。Hotstuff总结出对比了目前主流的BFT共识协议,构建了基于经典BFT共识实现pipeline BFT共识的模式。
HotStuff是尹茂帆等人提出的分布性一致性协议,在该算法中,最多出错节点个数为 f <= (n-1)/3 。
该算法有两个优点,第一个优点是,相比于之前的算法,HotStuff是基于leader节点的,拥有线性复杂度,可以极大地降低节点出错时,系统的共识消耗。同时,更替leader的低复杂度,鼓励网络频繁更迭leader节点,对于区块链等领域非常有用。第二个优点是该模型隔离了安全性与活跃性,安全性通过节点投票保证,而活跃性则通过Pacemaker保证。
学习HotStuff除了阅读本文,还可以阅读原论文《HotStuff: BFT Consensus in the Lens of Blockchain》,或是原论文的中文翻译。Facebook的Libra数字货币也使用的该算法的变种LibraBFT。
原论文提出了HotStuff的三种实现形式,分别为简易的HotStuff算法(Basic HotStuff),链状HotStuff算法(Chained HotStuff)和事件驱动的HotStuff算法(Event-driven HotStuff)。工程上,人们通常使用Event-driven HotStuff算法,但是如果直接去阅读Event-driven HotStuff算法的源代码会不知所云。
Event-driven HotStuff算法之所以比较难以理解,是因为它——
- 使用了Basic HotStuff算法的共识逻辑,特别的,包括leader如何与replica交互形成共识;
- 运用了Chained HotStuff提出的流水线优化思想,特别的,如何使用流水线并行优化原算法中相似的阶段;
- 最后Event-driven HotStuff是Chained HotStuff事件驱动形式,特别的,将原始实现中轮询产生的驱动改为由leader节点发出的事件驱动。
一方面,从论文的结构上来看,先介绍了前两者,最后才在Implementation章节介绍了Event-driven HotStuff。但另一方面,Event-driven HotStuff又是三者中代码最简单的,也是三者中唯一一个可以在网上找到大量源码进行对照的实现。因此直接上手阅读源码,在遇到困难时再去查阅简单版本的实现也是一个很好地做法(事实上论文作者也推荐直接阅读Event-driven HotStuff)。
2 协议内容
2.1 协议基础
名词解释
- BFT: 全称是Byzantine Fault tolerance, 表示系统可以容纳任意类型的错误,包括宕机、作恶等等。
- SMR: 全称是State Machine Replication, 一个状态机系统,系统的每个节点都有着相同的状态副本。
- BFT SMR protocol: 用来保证SMR中的各个正常节点都按照相同的顺序执行命令的一套协议。
- View: 表示一个共识单元,共识过程是由一个接一个的View组成的,每个View中都有一个ViewNumber表示,每个ViewNumber对应一个Leader。
- QC(quorum certificate): 表示一个被(n−f)个节点签名确认的数据包及viewNumber。比如,对某个区块的(n−f)个投票集合。
- prepareQC: 对于某个prepare消息,Leader收集齐(n−f)个节点签名所生成的证据(聚合签名或者是消息集合),可以视为第一轮投票达成的证据。
- lockedQC: 对于某个precommit消息,Leader收集齐(n−f)个节点签名所生成的证据(聚合签名或者是消息集合),可以视为第二轮投票达成的证据。
视图
状态机复制中单次状态转移在HotStuff中以视图(View)的形式出现,leader节点收集网络中其他节点的信息,发送提案并取得共识的整个过程可以看做是一个视图,视图实际上可以类比于状态机的一次转移,其中包含了这次转移需要执行的用户命令。而整个分布式系统,正是通过一次又一次的视图变换(View-Change),得以逐轮推进运作。
HotStuff是基于View的的共识协议,View表示一个共识单元,共识过程是由一个接一个的View组成。在一个View中,存在一个确定Leader来主导共识协议,并经过三阶段投票达成共识,然后切换到下一个View继续进行共识。假如遇到异常状况,某个View超时未能达成共识,也是切换到下一个View继续进行共识。
状态机复制 | State Machine Replication
状态机复制(State Machine Replication, SMR)是人们为了解决分布式系统同步问题提出的一种理论框架。为了让一个系统拥有较强的容错能力,人们通常会部署多个完全相同的副本节点,任意一个节点的崩溃都不会影响整个系统的正常工作。在工程上,这些副本节点通常使用状态机复制理论进行同步。副本状态机(SMR, State Machine Replication)指的是状态机由多个副本组成,在执行命令时,各个副本上的状态通过共识达成一致。
假如各个副本的初始状态是一致的,那么通过共识机制使得输入命令的顺序达成全局一致,就可以实现各个副本上状态的一致。
在SMR中,存在一个Leader节点发送proposal,然后各个节点参与投票达成共识。
系统输入为tx,网络节点负责将这些tx,打包成一个block,每个block都包含其父block的哈希索引。
分支
直观地看,HotStuff中,每一个副本节点都会在自己的内存中维护一个待提交指令的树状结构。每个树叶子节点都包含了一个待提交的指令,树节点到根节点组成了一个分支。未提交的分支之间互相是竞争关系,一轮中只会有一个分支被节点所共识。
系统中存在一个唯一的leader被其他所有节点所公认,这个leader会尝试将包含“待执行指令”的提议附加到一个已经被 n-f 个副本投票支持的分支。并尝试就新的分支与其他副本达成共识,共识成功后,整个系统所有节点都会提交并执行这些新的附加操作指令。
值得注意的是HotStuff并不关心leader的选取过程,因此在后续算法中,我们需要默认leader已经由其他模块指定。

仲裁证书
HotStuff中的投票使用密码学中的仲裁证书(Quorum Certificate, QC),每一个视图都会关联一个仲裁证书,仲裁证书表明该视图是否获得了足够多副本的认可。仲裁证书本质是副本节点通过自己的私钥签名的一种凭证。
如果一个副本节点认同某一个分支,它会使用自己的私钥对该分支签名,创建一个部分证书发送给leader。leader收集到 n-f 个部分证书,可以合成一个仲裁证书,一个拥有仲裁证书的视图意味着获得了多数节点的投票支持。
视图的投票总共分为三个步骤,准备阶段prepare, 预提交阶段pre-commit,提交阶段commit。每一次投票都会合成一个仲裁证书,不同阶段的证书从含义上稍微有些区别,在后续章节的阅读时需要注意。
网络假设
在实际的分布式系统中,由于网络延时、分区等因素,系统不是同步的系统。
在异步的网络系统,由FLP原理可知,各个节点不可能达成共识,因此对于分布式系统的分析,一般是基于部分同步假设的。
- 同步(synchrony):正常节点发出的消息,在已知的时间间隔内可以送达目标节点,即最大消息延迟是确定。
- 异步(asynchrony):正常节点发出消息,在一个时间间隔内可以送达目标节点,但是该时间间隔未知,即最大消息延迟未知。
- 部分同步(partially synchrony): 系统存在一个不确定的GST(global stable time)和一个Δ,使得在GST结束后的Δ时间内,系统处于一个同步状态。

2.2 Basic HotStuff 三阶段流程

2.2.1 Prepare阶段
每个View开始时,新的Leader收集由(n−f)个副本节点发送的NEW-VIEW消息,每个NEW-VIEW消息中包含了发送节点上高度最高的prepareQC(如果没有则设为空)。
prepareQC可以看做是对于某个区块(n−f)个节点的投票集合,共识过程中第一轮投票达成的证据
Leader从收到的NewView消息中,选取高度最高的preparedQC作为highQC。因为highQC是viewNumber最大的,所以不会有比它更高的区块得到确认,该区块所在的分支是安全的。
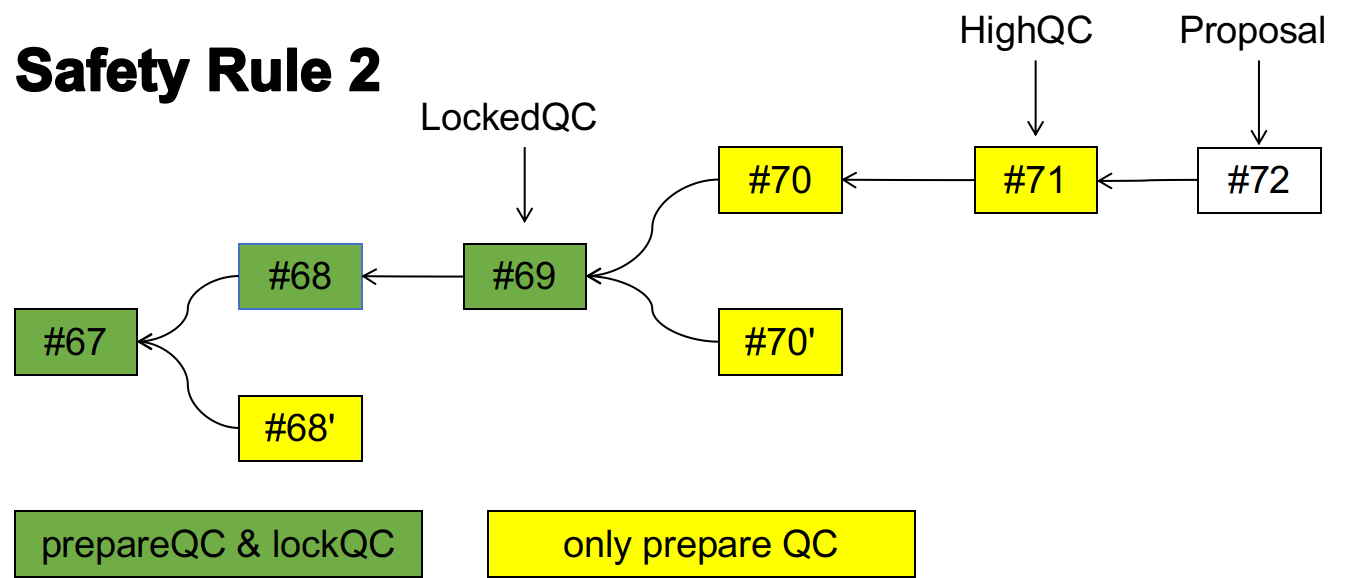
下图是Leader节点本地的区块树, #71是Leader节点收到的highQC, 那么阴影所表示的分支就是一个安全分支,基于该分支创建新的区块不会产生冲突。

Leader节点会在highQC所在的安全分支来创建一个新的区块,并广播proposal,proposal中包含了新的区块和highQC,其中highQC作为proposal的安全性验证。

其他节点(replica)一旦收到当前View对应Leader的Proposal消息,Replica会根据会SafeNode-predicate规则检查Proposal是否合法。如果Proposal合法,Replica会向Leader发送一个Prepare-vote(根据自己私钥份额对Proposal的签名)。
Replica对于Proposal的验证遵循如下的规则:
为保证Safety,Proposal消息中的区块是从本机lockedQC的区块扩展产生(即m.block是lockedQC.block的子孙区块)
在 HotStuff 中,每个节点都会维护一个 lockedQC,用于表示该节点已经看到的最高的已经被共识过的区块。当一个节点收到一个新的 Proposal 消息时,它需要检查其中的区块是否可以从自己的 lockedQC 扩展得到。
假设一个节点看到的 lockedQC 包含区块 A,它接下来收到了一个 Proposal,包含区块 B,而区块 B 并不能从区块 A 扩展得到。那么,这个节点就可以确定自己之前共识过的区块已经过时了,因为现在有另一个区块链分支已经比之前的更长了。如果这个节点现在继续支持之前的区块 A,那么它就会与其他节点产生分歧,从而导致共识的失败。
因此,HotStuff 协议要求每个节点在收到 Proposal 消息时,必须检查其中的区块是否可以从自己的 lockedQC 扩展得到,以确保所有节点在共识过程中都能够基于同样的区块链分支进行共识,从而保证共识的正确性。
为保证Liveness, 除了上一条之外,当Proposal.highQC高于本地lockedQC中的view_number时也会接收该proposal(说明自己被卡在了一个其他节点早已达成共识的视图,因此可以忽略自身的lockedQC,直接尝试与leader重新同步)。

safety判断规则对比的是lockedQC,而不是第一轮投票的结果,所以即使在上一轮针对A投了prepare票,假如A没有commit,那么下一轮依然可以对A’投票,所以说第一轮投票可以反悔。
2.2.2 Pre-commit
Leader发出proposal消息以后,等待(n−f)个节点对于该proposal的签名,集齐签名后会将这些签名组合成一个新的签名,以生成prepareQC保存在本地,然后将其放入PRECOMMIT消息中广播给Replica节点。
prepareQC可以表明有(n−f)个节点对相应的proposal进行了签名确认。
1
2
3
4
5
6
7
8
digraph prepare {
rankdir=LR;
Leader -> Replica1 [label="PRECOMMIT"]
Leader -> Replica2
Leader -> Replica3
Leader -> Replica4
}
- 在PBFT、Tendermint中,签名(投票)消息是节点间相互广播,各个节点都要做投票收集工作,所以对于每轮投票,Replica都需要至少验证(n−f)个签名。
- 在HotStuff中引入了门限签名方案,Replica利用各自的私钥份额签名,由Leader收集签名,Replica只需要将签名消息发送给Leader就可以。Leader将Replica的签名组装后,广播给Replica。这样HotStuff的一轮投票每个Replica只需要验证一次签名。
- 在HotStuff中,一轮投票的过程,是通过Replica与Leader的交互完成
- replica收到proposal,对其签名后,发送给Leader
- Leader集齐签名(投票)后,将签名(投票)组装,广播precommit消息
- replica收到Precommit,验证其中签名,验证通过则表示第一轮投票成功。
LibraBFT是基于HotStuff的共识协议,但是并没有采用HotStuff中的门限签名方案
当Replica收到Precommit消息时,会对其签名,然后回复给leader。
2.2.3 Commit
commit阶段与precommit阶段类似,当Leader收到当前Proposal的(n-f)个precommit-vote时,会将这些投票组合成precommitQC,然后将其放入COMMIT消息中广播。
当Replica收到COMMIT消息时,会对其签名commit-vote,然后回复给leader。更为重要的是,在此时,replica锁定在precommitQC上,将本地的lockQC更新成收到的precommitQC.
- 从Replica发出precommit-vote到Leader集齐消息并发出commit消息,这个过程相当于pbft、tendermint中的第二轮投票。
- Replica收到了commit消息,验证成功后,表示第二轮投票达成。此时Replica回复给Leader,并且保存precommitQC到lockedQC.
2.2.4 Decide
当Leader收到了(n-f)个commit-vote投票,将他们组合成commitQC,广播DECIDE消息。
Replica收到DECIDE消息中的commitQC后,认为当前proposal是一个确定的消息,然后执行已经确定的分支上的tx。View-Number加1,开始新的阶段。
- Note: 这里也是针对输入做共识,共识后再执行已经确定共识分支上的交易。
2.3 Safety
2.3.1 Safety性证明
2.3.1.1 同一个View下,不会对冲突的区块,产生相同类型的QC
证明思路: 反证法,假如在同一个view下,产生了相同类型的QC,而且最多存在f个作恶节点,那么就会有一个诚实节点双投了,这与前提假设矛盾。
- Lemma1: 对于任意两个有效的qc1、qc2,假如qc1.type==qc2.type,且qc1.block与qc2.block冲突,那么必然有qc1.viewNumber!=qc2.viewNumber.
证明(反证法):
1
2
3
4
假设 qc1.viewNumber == qc2.viewNumber
那么,在相同的 view 中,有 2f+1 个 replica 对 qc1.block 进行签名投票,同样有 2f+1 对 qc2.block 投票。
这样的话,就存在一个正常节点在算法流程中投了针对某个消息投了两票,这与算法流程冲突。
2.3.1.2 正常Replica不会commit冲突的区块
证明思路: 反证法,假如正常节点commit了冲突的区块,我们追踪到最早出现的冲突区块的位置,则这个冲突的位置肯定与两条safety规则相矛盾。
证明:
1. 根据 Lemma1 ,在相同的view下,正常的replica不会对冲突的区块产生commitQC,所以不会commit冲突的区块。
2. 下面证明在不同的view下,正常的replica也不会对冲突的区块产生commit
证明(反证法):
假设viewNumber在v1和v2时(v1 < v2),commit了冲突的区块,即存在commitQC_1 = {block1, v1}, commitQC_2={block2, v2},且block1与block2冲突。为了简化证明,我们同时假设v1与v2之间不存在其他的commitQC了,即commitQC_2是commit_1之后的第一个commitQC.
在v1和v2之间,肯定存在一个最小的v_s(v1 < v_s <= v2),使得v_s下存在有效的prepareQC_s{block_s, v_s},其中block_s与block1冲突.
当含有block_s的prepare被广播后,节点会对该消息做safety验证,由于block_s与block1冲突,所以显然,不符合safety规则1.
那么是否会符合规则2呢?
假如block_s.parent.viewNumber > block_1.viewNumber,那么显然block_s.parent与block_1冲突,所以block_s.parent是更早的与block1冲突的,这与v_s最小矛盾。
有2f+1个节点对于block_s的prepare消息投了票,那么这些节点在收到Prepare_s时,会进行safeNode验证,正常情况下,由于block_s与block1冲突,那么正常节点不会投出prepare_vote票,故而根本不会产生prepareQC_s, v_s根本不会存在. 这与上述假定冲突,因此在不同的view下,不可能对相同的block产生commit.
2.4 Chained HotStuff
在Basic HotStuff中,三阶段投票每一阶段无非都是发出消息然后收集投票,Chained HotStuff 改进了Basic HotStuff协议的效用,同时对其进行了简化。其思想是在每个 prepare 阶段都改变 view,也就是每个 proposal 都有自己的 view 。这减少了消息的种类,并使得决策可以流水线化处理。
在Chained HotStuff中,leader 将 prepare 阶段的投票收集到一个 view 中,形成一个genericQC。然后将此 genericQC 传递给下一个 view 中的 leader,实质上是将原本下一阶段(pre-commit)的责任委托给了下一个 leader。然而,下一个leader2 并不会真的执行 pre-commit 阶段,而是会启动一个新的 prepare 阶段,并添加自己的 proposal 。view v+1 的这个 prepare 阶段同时也是 view v 的 pre-commit 阶段。view v+2 的 prepare 阶段同时也是 viewv+1 的 pre-commit 阶段以及 view v 的 commit 阶段。因为所有阶段都具有相同的结构。
如图所示,Basic HotStuff 中阶段的流水线嵌入在了Chained HotStuff proposal 链中。
Chained HotStuff的 view v1、v2、v3分别作为 cmd1 在 v1 中提出的 prepare、pre-commit、commit 等Basic HotStuff阶段。该命令在 v4 结束时提交。
view v2、v3、v4分别作为 cmd2 在 v2 中提出的三个Basic HotStuff阶段。该命令在v5结束时提交。
在这些阶段中生成的其他 proposal 以类似的方式继续流水线处理,用虚线框表示。在图中,单箭头表示节点 b 的 b.parent 字段,双箭头表示 b.justify.node。

因此,在 Chained HotStuff 中只有两种消息类型,即 new-view 消息和通用阶段 (generic phase) 的 generic 消息。genericQC 在所有逻辑上流水线化的阶段中都起作用。
协议简化为如下过程:
- Leader节点
- 等待NewView消息,然后发出Proposal
- 发出Proposal后,等待其他节点的投票
- 向下一个Leader发出NewView消息
- 非Leader节点
- 等待来自Leader的Proposal消息
- 收到Leader的Proposal消息后,检查消息中的QC,更新本地的prepareQC、lockedQC等变量,发出投票
- 向下一Leader发出NewView消息
2.4.1 Dummy Block
正常情况下,每个View中都有一个区块产生并集齐签名,但是情况不会总是这么完美,有时不会有新的区块产生。为了保持区块高度与viewNumber的一致,HotStuff中引入了Dummy Block的概念。假如在一个View中,不能达成共识,那么就在为该View添加一个Dummy Block。

2.4.2 K-Chain

如图,当节点 b∗ 具有引用直接父节点的 QC 时,即 b∗.justify.node = b∗.parent 时,我们称 b* 形成 1-Chain。
记 b′′ = b∗.justify.node。在 b* 形成1-Chain 的基础上,若 b′′.justify.node = b′′.parent,则称 b* 形成2-Chain。
在此基础上,若 b′′ 形成 2-Chain,则 b* 形成 3-Chain。
一个区块中的QC是对其直接父区块的确认,那么我们称之为1-chain。同理,一个区块b后面没有Dummy block的情况下,连续产生了k个区块,则称这段区块链分支是对区块b的k-chain。
令 b = b′.justify.node,b′ = b′′.justify.node,b′′ = b*.justify.node,任何一个节点都可能出现祖先间隙。
如果 b* 形成 1-Chain,则 b′′ 的 prepare 阶段已成功。因此,当副本为 b* 投票时,还需要执行 genericQC ← b*.justify。
- 如果 b* 形成 2-Chain,则 b′ 的 pre-commit 阶段已成功。因此,副本应更新 lockedQC ← b′′.justify。
- 如果 b* 形成 3-Chain,则 b 的 commit 阶段已成功,b 成为已提交的决策。
每当一个新的区块形成,节点都会检查是否会形成1-chain,2-chian,3-chain.
- 1-chain: 有新的prepareQC形成,更新本地的 genericQC
- 2-chain: 有新的precommitQC形成,更新本地的 lockedQC
- 3-chian: 有新的commitQC形成,有新的区块分支进入 commit 状态,执行确认的区块分支
Chained HotStuff 协议伪代码:

2.4.3 Pacemaker
把 HotStuff 抽象成一个事件驱动的协议,可以将 liveness 相关的功能抽离出来,成为单独的 pacemaker 模块。safety 与 liveness 在实现上解耦,safety 是协议的核心保证安全性,liveness 由 pacemaker 保证。


- Pacemaker实现如下几部分功能
- Leader检查
- 收集NewView消息,对齐View并更新highQC
3 讨论
- BFT类共识算法研究对比: PBFT - Tendermint - HotStuff - Casper - GRANDPA
- PBFT: 两阶段投票,每个view有超时,viewchange通过一轮投票来完成,viewchange消息中包含了prepared消息(即达成了第一阶段投票的消息)。
- Tendermint: 两阶段投票,一个round中的各个阶段都有超时时间,roundchange通过超时触发(而不是投票),网络节点保存自己已经达成第一阶段投票的消息(即polka消息)。
- HotStuff: 三阶段投票,每个view有超时,采用门限签名减小消息复杂度。liveness与safety解耦为两个部分
- GRANDPA: 将出块与共识确认分离,用来对已经产生的区块链进行投票确认,两阶段投票,但是投票是针对区块分支(对一个区块投票也相当于对其所有父区块投票),而不是特定区块,各个节点可以针对不同高度的区块投票